
YANG Message Keys for Message Broker Integration is a brand new IETF draft, with the great potential to ease network operations. In one sentence, it’s about a mechanism to define a unique message key for a YANG to message broker integration and a topic addressing scheme based on YANG-Push subscription type and a YANG index.
Not quite obvious how to make the link with the blog title, right? Let’s decompose this.
Some background first, about the trend to move to the IETF YANG-Push for telemetry, directly into a message broker (Kafka), up to the time series database (TSDB), to keep the YANG semantic and associate the relevant metadata for further analysis. See the IETF Network Management Operations (nmop) work and, more specifically, this An Architecture for YANG-Push to Message Broker Integration figure, by Thomas Graf and Ahmed Elhassany.
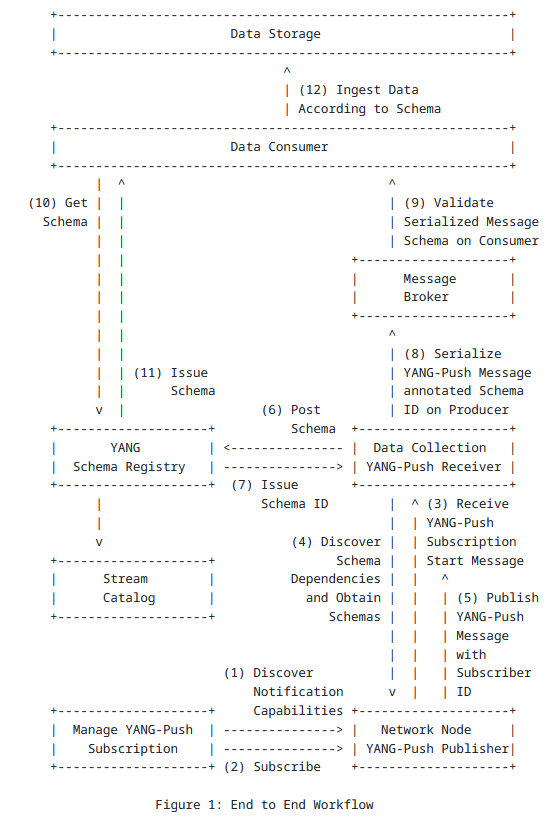
This architecture is a good start. However, currently, without a well‑defined message key and topic partitioning scheme, all the data ends up being put into a single Kafka topic, and distributed, for load balancing, in a round robin fashion across partitions. Because of this, consumers must read all partitions and then filter afterwards to extract just the subset of data they are interested in (e.g. for a particular network node or component). This creates unnecessary data processing overhead, limits scalability, and degrades real-time performance—especially for analytics use cases.
Building on top of this architecture with Thomas Graf as leader, Ahmed Elhassany and Alex Huang Feng (we don’t change a winning team!), we thought about indexing the YANG-Push telemetry data (types) for optimal consumption.
Typically, YANG telemetry data can be subscribed in three ways:
- “periodically”, for statistical metrics (typically example: the interface counters)
- “on-change” for state changes (typically example: link-up or link-down)
- “on-change with sync-on-start”, for states, with a complete “push-update” of all subscribed data will be sent at the beginning of a subscription (see section 3.1 of RFC 8641)
This document proposes to include “statistics”, “states” and “state-changes” in the Kafka topic name as the first part to denote the types of data. On top of that, a YANG index is generated from the YANG schema nodes and list keys to create the Kafka message key. On the consumer side, a network operator or network management application can use a wildcard for the query … either the data types or specific YANG data nodes. For example, a query on “project.environment.state-changes.yang.*“
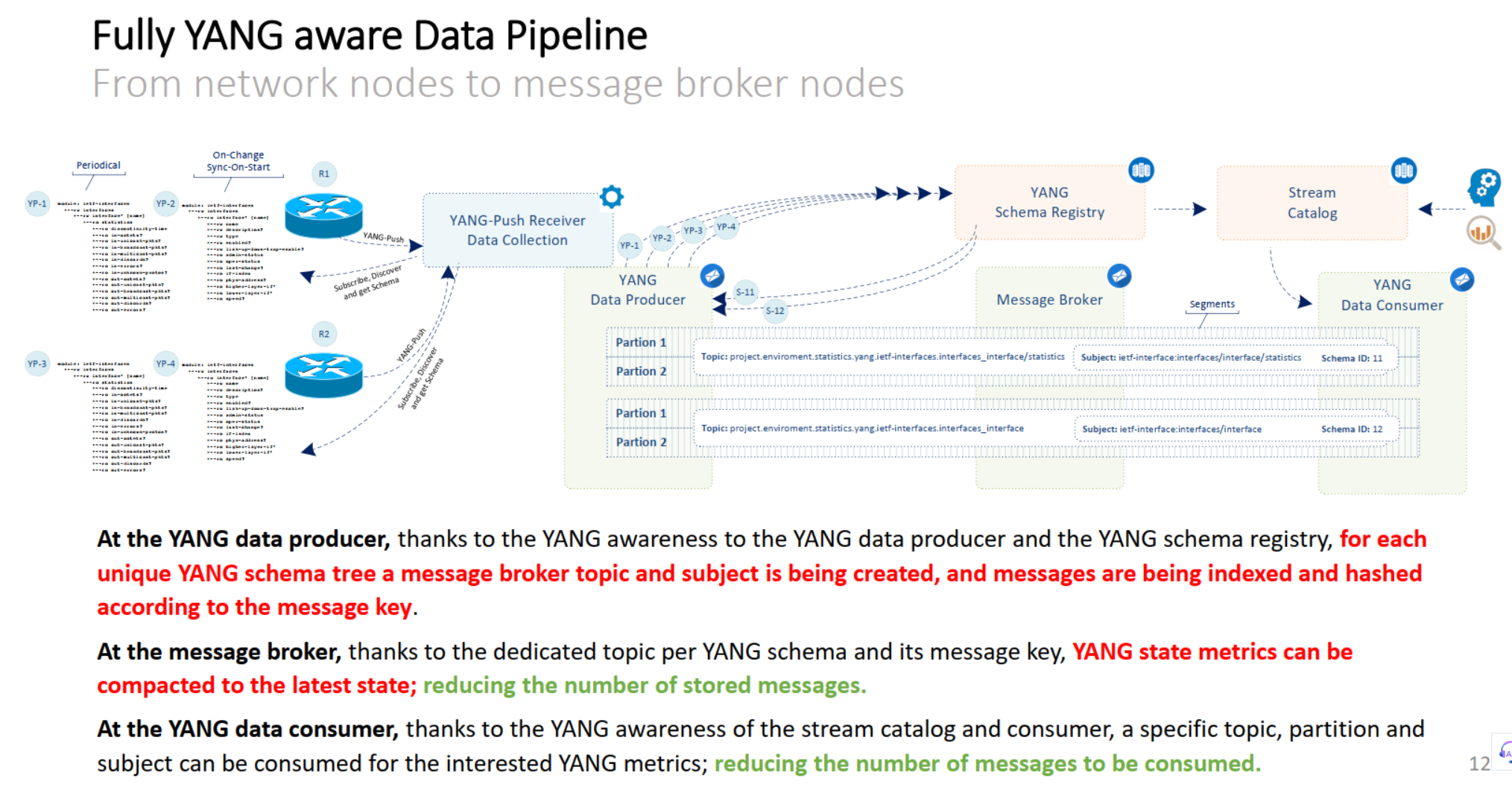
Below is the full architecture, presented by Thomas:
Kafka Topic Compaction
Kafka Topic compaction is a feature that ensures the latest value for each unique key within a topic is retained, even as older records are deleted. Unlike regular log retention, which removes data based on time or size, topic compaction periodically removes obsolete records and keeps at least the most recent update for every key. This is particularly useful for topics that act as a persistent, up-to-date snapshot of data, such configuration settings, network state, or user profiles, allowing consumers to reconstruct the current state of the data efficiently. So, this is ideal for stateful applications.
IETF YANG-Push On-Change Sync-On-Start
The IETF YANG-Push on-change sync-on-Start is a feature that allows a subscriber to receive the current state of the subscribed data immediately after the subscription is established. This is particularly useful in scenarios where the subscriber needs to have a complete and accurate view of the data from the beginning, rather than waiting for updates or changes. For example: network inventory, topology mapping, or state monitoring, where knowing the baseline state is essential.
Without the on-change sync-on-start, a subscriber only receives future changes, not the current state. This can lead to incomplete or inconsistent views of the data.
Reference: Section 3.1 of Subscription to YANG Notifications for Datastore Updates, RFC 8641
Why Is This A Game Changer For Network Operations?
First off, at the YANG data consumer side, thanks to the YANG awareness of the “stream catalog”, a specific topic, partition and subject can be consumed for the interested YANG metrics, either per YANG type or specific YANG leaves… reducing the number of messages to be consumed. No more need to query all the nodes, resulting in more efficient network operations, with
- lower latency: Fast access to relevant data
- better scalability: Efficient data indexing and retrieval.
The biggest advantage to me is the combination of Kafka topic compaction feature with the IETF YANG-push “on-change with sync-on-start”.
As a first example, imagine that your preferred analytics application recovers from a failure. This application requires the network topology as input (called Service & Infrastructure Maps – SIMAP at the IETF; sometimes called digital map).
As a second example, imagine you want to evaluate a brand analytics/AI application that requires the network topology/SIMAP as one of the input. As network operator, you currently have two options, to provide the data. Either you provide the new application with access to all network routers or with access to you TSDB. Both cases are not ideal. The industry trend, with all operators having a data mesh big data architecture, is that the data collection remains the operator ownership, with minimal external interactions with the network (even for telemetry collection) and no external access to the TSDB.
With the combination of “on-change with sync-on-start” and topic compaction, and the network state will remain forever (by default) in the topic. By providing this feed, both examples above are resolved, in no time. This is the beauty of this new feature. Convinced?