
Reflecting about automation lately, I realized that the messaging changed along the years, the more we learned about networking service automation.

About 10 years ago, I used to make the following statement in my presentations.
Automation is as good as the data models.
This was the beginning of the new data model-driven management new paradigm, with the YANG (models) standardization at the IETF. The number of RFC-produced YANG modules was an important metric, if not the primary one, at that time. Obviously, with more standardized models, automation is simplified.
Having models was a step in the right direction. However, the industry/community did not lose track of the end goal: automation. And automation requires some tools. Hence, in parallel, tools were developed: some in opensource, some others as commercial products. At the first IETF hackathon in 2015, a bunch of us started to create tools to validate and organize those YANG modules. This was the beginning of what would become the yangcatalog.org. The mission was (and still is) to help with the creation and organization of the models, not only for IETF, but also for different Standard Development Organizations (SDOs), for opensource projects, and for vendors with their vendor-specific models.
To highlight the importance of tools in the automation chain, and to stress the importance for network operators of testing and developing their toolchain, my statement became:
Automation is as good as your data models and your toolchain
Btw, a toolchain is good but a stable toolchain is better. On that front, happy to remind you that the YANG catalog transitioned to the IETF LLC a year ago, guaranteeing that way some permanent support. This implies that the YANG catalog can be a stable building block in YOUR toolchain.
While “playing” with the toolchain and selecting the right YANG modules for automation, we came to the realization that the models metadata are essential. For any YANG model, and actually for any particular revision of a model, typical questions are:
- Does the model come from a specific SDO, open-source project or is vendor-specific? If from a SDO, is this a ratified standard? Or the model is still a draft? Or maybe it expired?
- Is there any supporting document? Can we contact the authors?
- Is this a network-element or a network service model? Is this a module or a submodule?
- What is the model structure? NMDA-compatible (Network Management Datastore Architecture, RFC 8342), openconfig, split, transitional-extra, or unknown. The advice being that, for service development, it might be best to stick to one model structure in order to ease the mapping between service and network element models in an orchestrator.
- Does the model require the implementation of other models (import YANG statement)?
- What is the semantic versioning compared to a previous revision? In other words, will my model-based scripts break because of non backward compatible changes?
- Where is the model implemented? When implemented, are there deviations?
- Etc.
All the questions could be answered by associating metadata with specific model revision. Some metadata can be extracted from the YANG module, while some others need to be explicitly set . We organized the YANG catalog to display all these metadata handy.
Below is the example of the ietf-yang-library (RFC 8525) metadata.
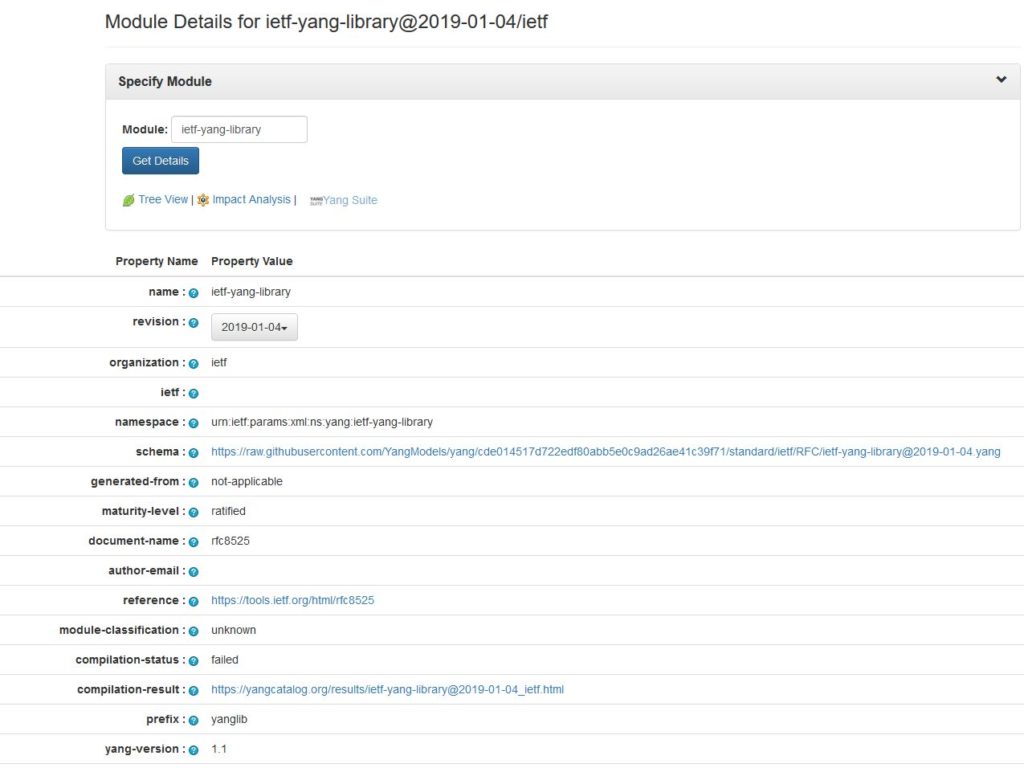
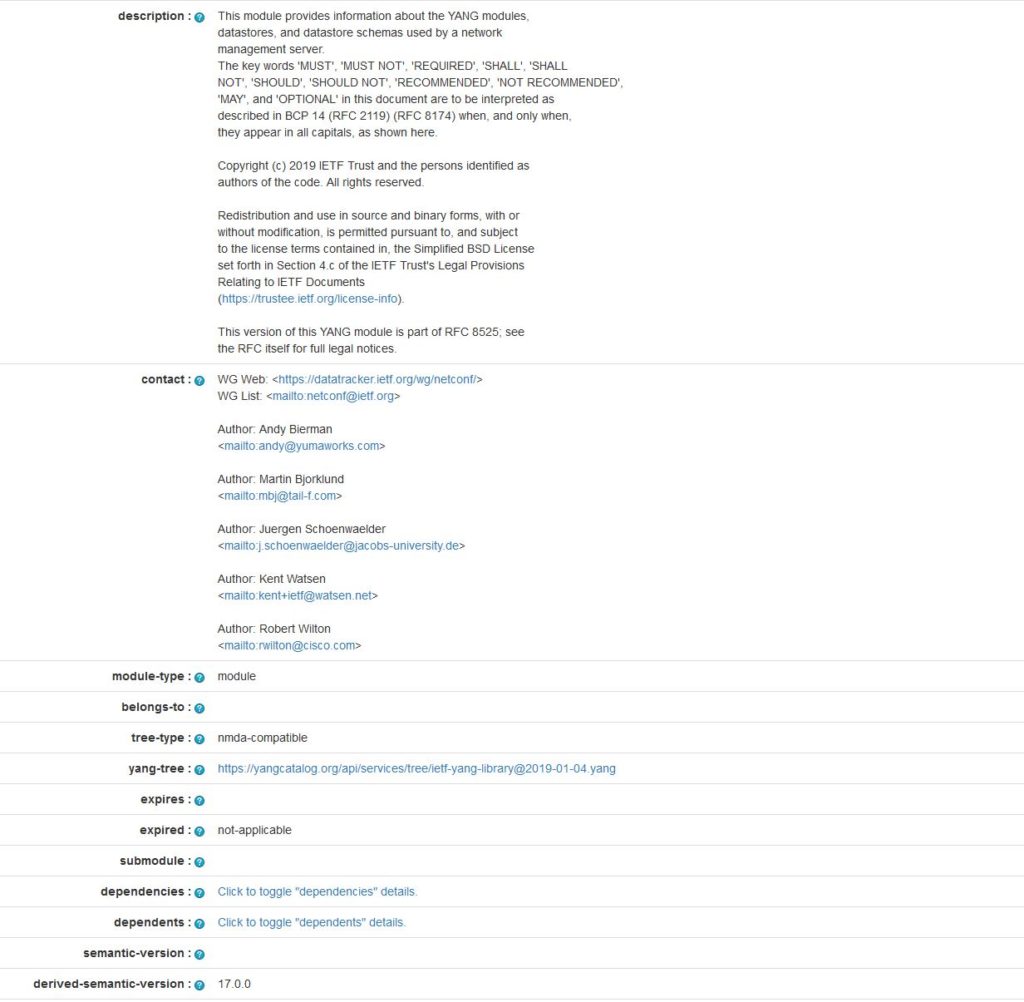
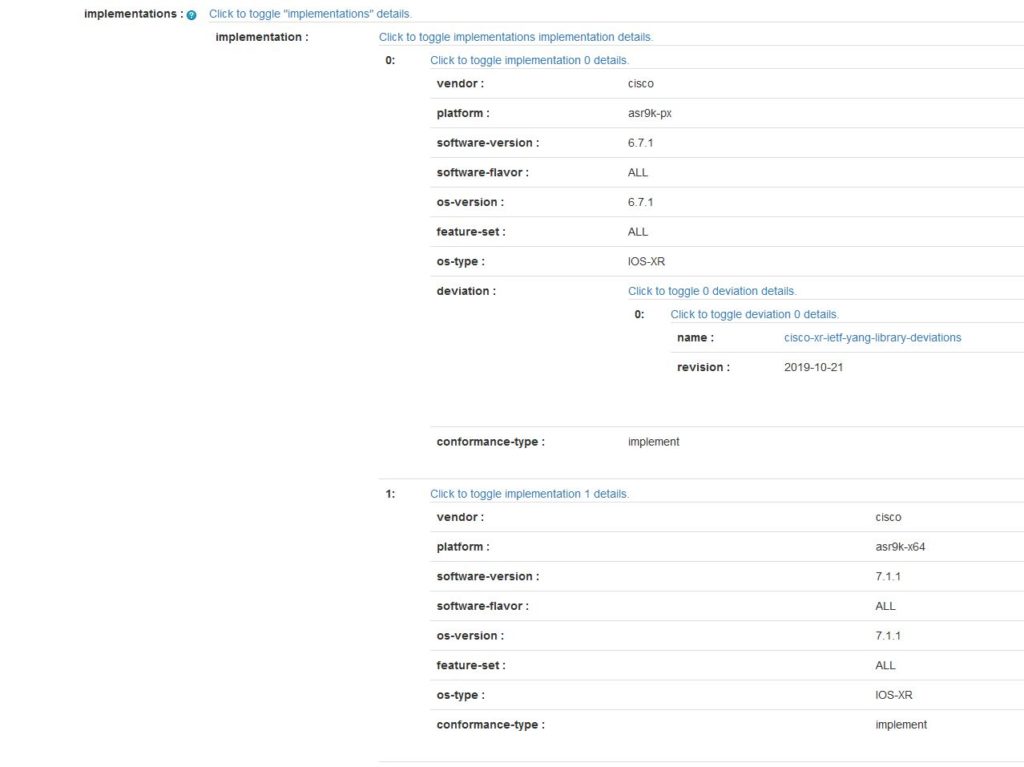
For the details regarding the metadata, have a look at this IETF draft. Joe Clarke and I never bothered trying to standardize this draft, as we knew that the YANG module to access the YANG catalog would be a living beast, evolving with the latest needs. Indeed, more metadata will certainly follow.
At that point in time in history, my new statement became:
Automation is as good as your data models, their related metadata, and your toolchain
Now, the latest realization is that this statement is still incomplete. Automation is not only config management, but also using telemetry to stream the operational states, to assure services, and to close the loop for intent-based networking.
If we rely on telemetry, we must understand, for each YANG object, information such as: minimum-dampening-period, on-change-supported, periodic-notifications-supported, and supported-excluded-change-type. Those leaf-specific metadata are specified in draft-ietf-netconf-notification-capabilities, currently in WG last call.
And more per-node capabilities (btw, this is a better name than the leaf-specific metadata) are required for optimum operational data collection.
This brand new IETF draft proposes more per-node capabilities:
- minimum-observable-period: This is the minimum observable period. For example, let’s assume a packet counter is only updated every 30 sec. If you would stream (or poll) every 5 seconds, you would wrongly conclude that no more packets arrive/leave and try to correct this non-problem.
- suggested-observable-period: The suggested observable period for his node-selector. This value represents factory default suggested information, only available at implementation time.
- optimized-measurement-point: In some server design, operational data are usually modeled/structured in a way that the relevant data are grouped together and reside together. In most cases, it is more performant to fetch this data together than as individual leaves
- related-node: In the (old) world of MIB modules, we know that the ifAdminStatus and ifOperStatus MIB objects are linked, the first one being the configuration object and the latter the operational object. However, there is no automatic way to discover this relationship.
In YANG, we have two ways to structure the modules to solve this problem: the openconfig structure and the latest NMDA [RFC8342]. However, if a YANG module does not fit into those two categories, for example because this is a older or generated module, we need to document this behavior with the related-node.
In case the node-capability is an operational node then the related-node is the associated node-instance-identifier representing the config paths directly related to this operational node capabilities.
In case the node-capability is an config node then the related-node is the associated node-instance-identifier representing the operational leaf directly related to this configuration node capabilities.
And now, the most up-to-date statement becomes, until we learn some more…
Automation is as good as your data models, their related metadata & per-node capabilities, and your toolchain.
If I want to focus the messaging on the WHY instead of HOW, the statement is actually
Automation is as good as your data models, their related metadata & per-node capabilities, your toolchain, and what you can do with them.
The IETF and the industry have been and are still actively working on those topics.